背景
SH-WEB 博客架构运行在腾讯云上海 VPC 内,由 CLB 负载均衡、3 台 CVM(1 台跳板机 + 2 台竞价实例)、TDSQL-C MySQL、Redis 组成。此前已通过腾讯云 CLS 采集应用日志、CloudQ 进行架构巡检,但存在两个核心问题:
- 可观测数据分散:基础设施指标在云监控、应用日志在 CLS、数据库状态在控制台——排障时需要多处切换,缺少统一的全栈可观测平台
- AI 诊断数据断层:智能顾问 CloudQ 能分析架构图和云监控数据,但无法触达 APM 链路、应用级指标和数据库详细监控,诊断深度受限
本文记录了一套完整的解决方案:部署观测云(Guance Cloud)实现全栈可观测,再通过 MCP 协议将观测数据接入智能顾问 CloudQ,让 AI 能够结合架构图 + 云监控 + APM 链路 + 数据库/缓存指标进行多源联合诊断。最终实现了从基础设施到应用层的端到端可观测闭环。
架构
SH-WEB 架构观测云监控部署架构
核心要点:
- DataKit:观测云官方 Agent,部署在每台 CVM 上,统一采集主机指标、APM 链路、数据库/缓存数据
- dd-trace:Datadog 开源的 Node.js 链路追踪 SDK,自动埋点 Express/MySQL/Redis
- Nginx 代理:竞价实例无公网 IP,通过跳板机 Nginx 反向代理将数据转发到观测云
Step 1:安装 DataKit — 构建基础设施数据底座
DataKit 是观测云的数据采集 Agent,安装后默认采集主机基础指标(CPU、内存、磁盘、网络等)。这些数据通过 MCP 接入 CloudQ 后,AI 可以直接查询主机健康状态,与架构图中的 CVM 节点关联分析。
跳板机(有公网 IP)
DK_DATAWAY="https://openway.guance.com?token=<你的Token>" \
bash -c "$(curl -L https://static.guance.com/datakit/install.sh)"
竞价实例(无公网 IP)
竞价实例没有公网 IP,无法直接下载 DataKit 也无法上报数据。解决方案是从跳板机 rsync 整个安装目录:
rsync -az root@172.17.0.17:/usr/local/datakit/ /usr/local/datakit/
scp root@172.17.0.17:/etc/systemd/system/datakit.service /etc/systemd/system/
ln -sf /usr/local/datakit/datakit /usr/local/bin/datakit
# 启动
systemctl daemon-reload && systemctl enable datakit && systemctl start datakit
关键发现:竞价实例没有公网 IP 时,DataKit 安装脚本会因curl超时而失败,且即使安装成功也无法上报数据(all-retry-failed)。这是部署过程中最主要的坑。
Step 2:Nginx 代理 — 让无公网实例也能上报
竞价实例没有公网 IP,无法直连观测云数据网关。通过跳板机 Nginx 反向代理解决这一问题,确保所有实例的可观测数据都能完整上报,避免 CloudQ 诊断时出现数据盲区。
server {
listen 9530;
client_max_body_size 10m;
location / {
proxy_pass https://openway.guance.com;
proxy_http_version 1.1;
proxy_set_header Host openway.guance.com;
proxy_ssl_server_name on;
proxy_ssl_name openway.guance.com;
proxy_connect_timeout 10s;
proxy_read_timeout 30s;
}
}
然后修改竞价实例的 DataKit 配置,将上报地址改为跳板机内网:
[dataway]
urls = ["http://172.17.0.17:9530?token=<Token>"]
修改后重启 DataKit,之前满屏的 all-retry-failed 错误彻底消失,数据通过内网 → 跳板机 → 公网成功上报。
Step 3:配置 MySQL 采集器 — 数据库层可观测
MySQL 采集器为 CloudQ 提供数据库层的深度监控数据——连接数、QPS、慢查询、InnoDB 状态等。此前 CloudQ 只能看到 TDSQL-C 的基础云监控指标,接入观测云后可以获取 DBM(数据库活动监控)级别的细粒度数据。
采集器只需在跳板机上配置(避免多台重复采集同一数据库):
[[inputs.mysql]]
host = "172.17.0.10"
user = "root"
pass = "***"
port = 3306
interval = "30s"
innodb = true
election = true
[inputs.mysql.dbm_metric]
enabled = true
[inputs.mysql.dbm_sample]
enabled = true
[inputs.mysql.dbm_activity]
enabled = true
[inputs.mysql.tags]
service = "sh-web-mysql"
env = "production"
采集指标包括:连接数、QPS/TPS、InnoDB 缓冲池、慢查询、锁等待、数据库活动监控(DBM)等。
Step 4:配置 Redis 采集器 — 缓存层可观测
Redis 采集器为 CloudQ 补齐缓存层的监控数据,包括内存使用率、命中率、延迟分布、慢查询和大 Key 等,使 AI 诊断能够覆盖到缓存层的性能瓶颈。
[[inputs.redis]]
host = "172.17.0.14"
port = 6379
interval = "30s"
slow_log = true
latency_percentiles = true
election = true
[inputs.redis.hot_big_keys]
enable = true
[inputs.redis.tags]
service = "sh-web-redis"
env = "production"
踩坑记录:腾讯云 Redis 实例的认证方式与配置中的username参数不兼容。初次配置时使用了username = "root"导致WRONGPASS错误;去掉 username 后又报no password is set。最终确认该 VPC 内的 Redis 实例未启用密码认证,去掉密码配置后正常采集。
Step 5:接入 APM 链路追踪 — 应用层全链路可观测
APM 链路追踪是本次接入的核心价值——它让 CloudQ 能够看到每一次请求从 Express 路由到 MySQL 查询再到 Redis 缓存的完整调用链,精确定位应用层的性能瓶颈和错误根因。这是此前云监控和 CLS 日志都无法提供的维度。
SH-WEB 是 Node.js Express 应用,使用 dd-trace(Datadog 开源链路追踪 SDK)实现零代码侵入的全链路追踪。
5.1 开启 DataKit DDTrace 采集器
[[inputs.ddtrace]]
endpoints = ["/v0.3/traces", "/v0.4/traces", "/v0.5/traces"]
keep_rare_resource = true
trace_128_bit_id = true
tracing_metric_enable = true
[inputs.ddtrace.sampler]
sampling_rate = 1.0
5.2 安装 dd-trace 并初始化
创建 tracer.js:
const tracer = require('dd-trace').init({
service: 'sh-web-blog',
env: 'production',
version: '1.0.0',
hostname: 'localhost',
port: 9529,
logInjection: true,
});
module.exports = tracer;
在 app.js 最顶部(第一行)添加:
const express = require('express');
// ... 其余代码不变
自动埋点覆盖:dd-trace 会自动拦截 Express(HTTP 请求/响应/路由)、mysql2(SQL 查询/耗时)、ioredis(Redis 命令/耗时)、http/https(外部调用)的所有操作,无需手动埋点。
5.3 验证
部署后产生几次请求访问,通过 DataKit 的 metrics 端点确认数据接收:
# datakit_input_ddtrace_trace_spans_sum{input="ddtrace"} 1234
# datakit_input_ddtrace_trace_spans_count{input="ddtrace"} 212
212 个 trace、1234 个 span 成功上报。
Step 6:Auto Scaling 自动接入 — 确保数据持续完整
竞价实例可能被回收重建,如果新实例没有 DataKit 和 dd-trace,CloudQ 诊断时就会出现数据缺失。在 startup.sh 中集成自动安装逻辑,确保扩缩容后可观测数据始终完整:
# 安装 npm 依赖(包括 dd-trace)
cd /opt/tech-blog
/usr/local/node/bin/npm install --production
# 安装 DataKit(从跳板机同步)
if [ ! -f /usr/local/datakit/datakit ]; then
rsync -az root@$JUMP_SERVER:/usr/local/datakit/ /usr/local/datakit/
rsync -az root@$JUMP_SERVER:/etc/systemd/system/datakit.service /etc/systemd/system/
# 切换为跳板机代理上报
sed -i "s|https://openway.guance.com|http://$JUMP_SERVER:9530|" \
/usr/local/datakit/conf.d/datakit.conf
# 移除 MySQL/Redis 采集器(跳板机已采集)
rm -f /usr/local/datakit/conf.d/mysql.conf /usr/local/datakit/conf.d/redis.conf
systemctl daemon-reload && systemctl enable datakit
fi
systemctl restart datakit
踩坑总结
| 问题 | 现象 | 解决 |
|---|---|---|
| 竞价实例无公网 IP | DataKit 安装脚本 curl 超时,上报 all-retry-failed | 从跳板机 rsync 安装 + Nginx 9530 端口反向代理上报 |
| Redis 认证失败 | WRONGPASS invalid username-password pair | 腾讯云 Redis 不支持 username 参数,去掉后又发现未启用密码,最终移除所有认证配置 |
| dd-trace module not found | deploy.sh 同步代码后服务启动失败 | dd-trace 装在 repo 目录但运行目录是 /opt/tech-blog,需在运行目录也 npm install |
| 竞价实例 npm 不在 PATH | npm: command not found | 需要完整路径 /usr/local/node/bin/npm |
可观测数据底座就绪
至此,观测云 DataKit 已在 3 台 CVM 上完成全量部署,形成了完整的可观测数据底座,为下一步接入 CloudQ MCP 提供数据支撑:
| 监控维度 | 采集方式 | 覆盖范围 |
|---|---|---|
| 基础设施 | DataKit 默认采集器 | 3 台 CVM 的 CPU、内存、磁盘、网络、进程 |
| 数据库 | DataKit MySQL 采集器 | 连接数、QPS、InnoDB、慢查询、DBM |
| 缓存 | DataKit Redis 采集器 | 内存、命中率、延迟、慢查询、大 Key |
| APM 链路追踪 | dd-trace → DataKit DDTrace | Express HTTP → MySQL 查询 → Redis 命令全链路 |
Step 7:接入智能顾问 CloudQ MCP — 核心:AI 多源联合诊断
前面 6 步构建了完整的可观测数据底座,但数据本身不是目的——让 AI 能够利用这些数据做智能诊断才是关键。通过 MCP(Model Context Protocol)将观测云接入智能顾问 CloudQ,AI 就能同时看到架构图、云监控、APM 链路、数据库/缓存指标,实现真正的多源联合诊断。
观测云提供了官方 MCP Server,支持 Streamable HTTP 协议,智能顾问的自定义 MCP 连接器可以直接对接。
7.1 获取观测云 API Key
在观测云控制台 → 工作空间管理 → API Keys,创建一个 API Key。
7.2 确定 MCP Endpoint
根据工作空间所属站点选择对应的 Owl MCP Endpoint:
| 站点 | Endpoint |
|---|---|
| 中国区1(杭州) | https://owl-mcp.guance.com/mcp |
| 中国区4(广州) | https://cn4-owl-mcp.guance.com/mcp |
| 中国区2(宁夏) | https://aws-owl-mcp.guance.com/mcp |
7.3 在智能顾问控制台配置
在腾讯云智能顾问控制台 → 自定义 MCP → 添加连接:
| 配置项 | 值 |
|---|---|
| 协议类型 | Streamable HTTP |
| URL | https://owl-mcp.guance.com/mcp(按站点选择) |
| Header Key | Authorization |
| Header Value | Bearer <你的API Key> |
7.4 可用工具
MCP 接入后,CloudQ 可调用观测云 40+ 工具,核心包括:
| 工具 | 功能 | 典型用法 |
|---|---|---|
owl.data.query | DQL 查询 | "查询最近1小时CPU使用率" |
owl.infrastructure.list | 基础设施列表 | "列出所有主机状态" |
owl.apm.list | APM 服务列表 | "查看APM链路服务" |
owl.monitor.list | 监控器列表 | "查看当前告警规则" |
owl.event.list | 事件列表 | "最近有哪些告警事件" |
7.5 效果验证
配置完成后在 CloudQ 中提问验证:
"查询观测云中 sh-web-blog 服务的 APM 链路数据"
CloudQ 会自动调用 exec_tool → owl.apm.list 等工具查询观测云数据,返回 3 个 APM 服务(sh-web-blog、sh-web-blog-mysql、sh-web-blog-redis)的链路信息。
下图为智能顾问 CloudQ 通过观测云 MCP 查询到的 APM 链路数据,展示了多源联合诊断的实际效果:
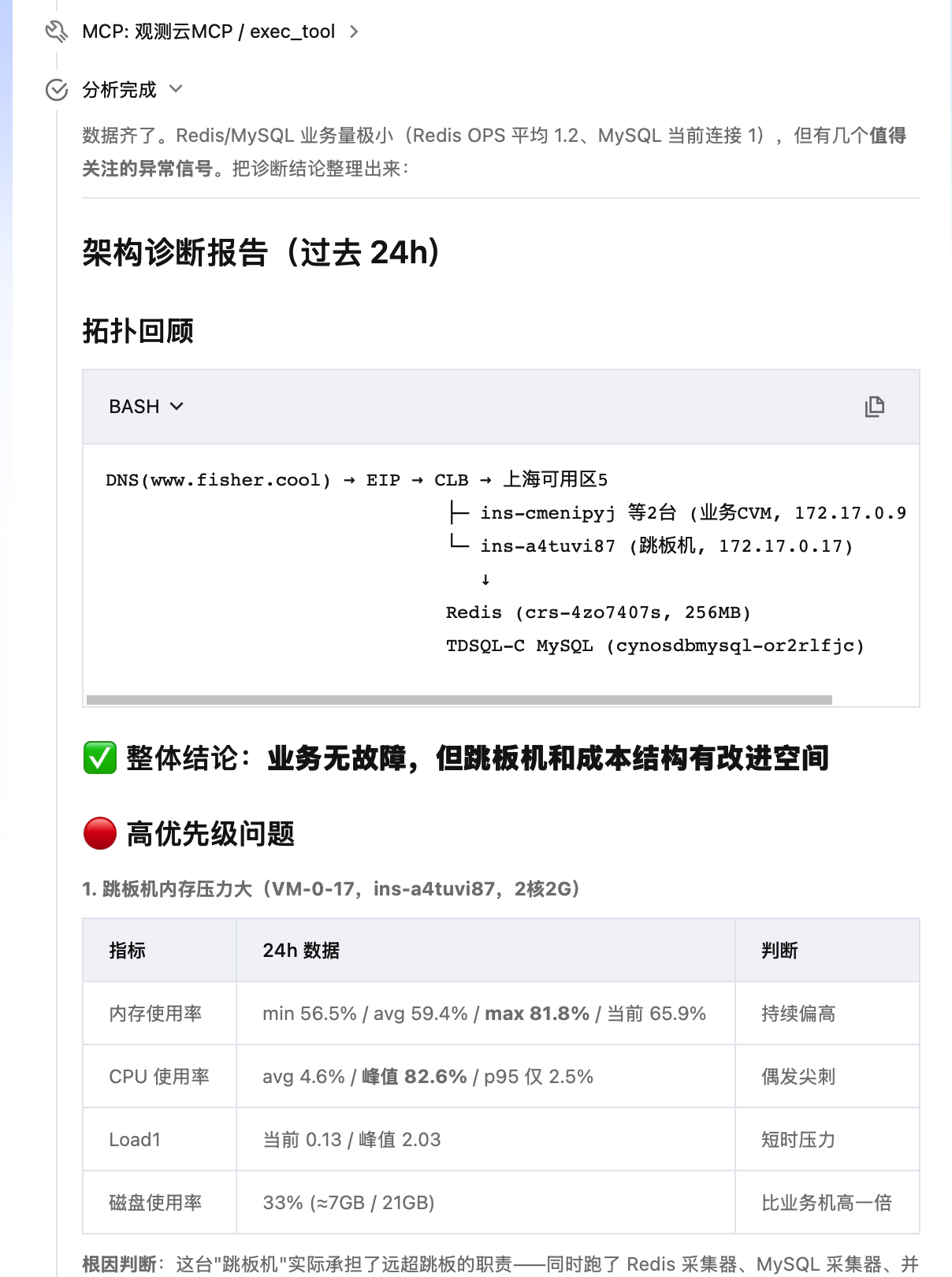
智能顾问 CloudQ 通过观测云 MCP 查询到 sh-web-blog 服务的 APM 链路追踪数据
多源联合诊断:至此,CloudQ 同时具备三个数据源——腾讯云原生能力(架构图巡检、云监控、CLS 日志)、阿里云 SLS MCP(跨云日志)、观测云 MCP(DataKit 基础设施 + APM 链路 + MySQL/Redis 监控),实现了完整的多源可观测诊断能力。
总结:本文实现了从"部署可观测"到"AI 智能诊断"的完整闭环:
第一层:可观测数据底座 — 通过观测云 DataKit + dd-trace,仅修改一行代码即实现全栈可观测(基础设施 + APM 链路 + MySQL + Redis)
第二层:AI 多源联合诊断 — 通过 MCP 协议将观测云接入智能顾问 CloudQ,让 AI 能够结合架构图 + 云监控 + APM 链路 + 数据库指标进行综合诊断,覆盖从基础设施到应用层的全链路
第三层:多云统一视图 — CloudQ 同时接入腾讯云原生能力、阿里云 SLS MCP、观测云 MCP 三个数据源,形成多云多源的统一可观测诊断平台
整个部署过程最大的挑战不在配置本身,而在于竞价实例无公网 IP 导致的安装和上报问题——通过 Nginx 反向代理优雅解决。这套"跳板机代理上报 + MCP 打通 AI 诊断"的模式,对于需要在混合架构中构建智能运维能力的场景具有通用参考价值。